PyTorch手写多头注意力
上回说到了 self-attention 的四种写法,这次更新一下
multi-head attention
的写法。multi-head attention 与 self-attention
最主要的不同是,我们输入的 X (Batch_size, seq_size, emb_size) 在
self-attention 的 QKV 均为 (Batch_size, seq_size,
emb_size), 而在 multi-head attention 中,我们需要将
emb_size 拆分为 num_head 和
head_dim。
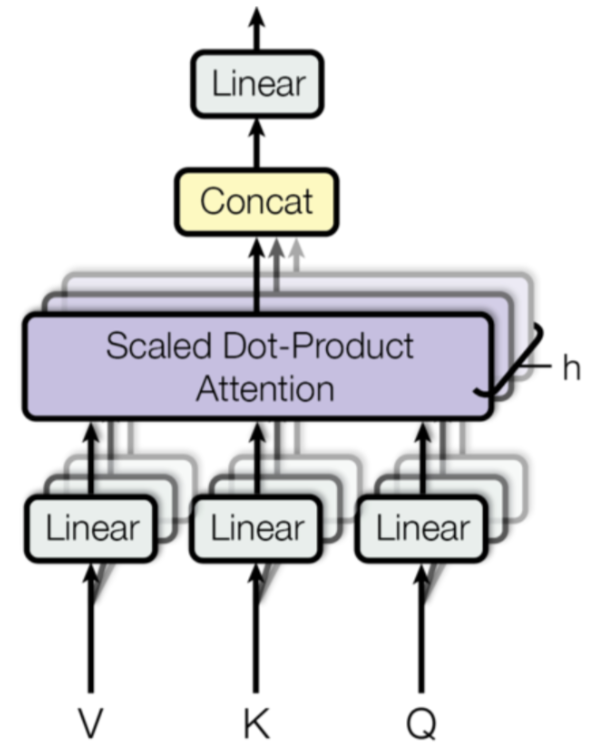
多头注意力通过并行地运行多个独立的注意力机制来获取输入序列的不同子空间的注意力分布,从而更全面地捕获序列中潜在的多种语义关联。
代码如下所示:
1 | import torch |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2025-02-22
attention的四重境界
LLM随着最近deepseek的热潮被推上了新的高峰,楼主在学习之中对于attention的理解也有着不同的见解,借此机会重新试着手写一下attention。 见山是山,Attention Atttetion 的公式如下所示,是大家都很熟悉的在Attention is all you need文章中的 \[ Atttention(Q, K, V) = softmax(\frac{QK^T}{d_k})V \] 对于此的复现也是较为容易,我们可以构建一个Attention的类来根据公式进行复现 123456789101112131415161718192021222324252627282930313233343536373839404142434445import torchimport torch.nn as nnimport mathclass AttentionClass(nn.Module): def __init__(self, hidden_dim: int = 748) -> None: super().__init__() ...
2025-12-04
中国互联网大厂大模型求职指南
从 2023 年 ChatGPT 发布开始,大模型就成为国内互联网大厂的招聘重点。从预训练、后训练算法到 AI Infra,从大模型产品到大模型运营,相关岗位的薪资也随之水涨船高。 根据公开报道和我掌握的零散信息,2024 年清北或海外名校的大模型相关专业博士,进入互联网大厂顶尖人才计划的,拿到的校招 offer 大致在 150 万左右,顶级档位是字节 3-1 或者腾讯 9/10 级。而到了今年,各大厂再次加码,在顶尖人才计划中的清北博士们,校招生 offer 已经普遍涨到 200 万以上。个别顶级候选人,在校招阶段就有机会拿到字节 4-1、腾讯 T12 等档位,对应 400~500 万量级的整体薪酬包(不同公司口径略有差异)。 除了“疯狂”的校招生之外,众多算法大佬被高薪挖走的消息也是屡见不鲜:从传言中周畅 4 年 5000 万人民币被字节挖走,到字节 Seed 的乔思远 4 年 5000 万美元加入 Meta。具体数字未必完全准确,但可以肯定的是,在这些传闻里,一个字节 3-1 或 3-2 的研究员跳槽到硅谷,往往都能拿到数百万美元级别的薪酬(这也被不少人视为字节 Seed...
Comments